ElasticSearch 에서의 클러스터와 노드의 대한 개념 이해하기
ElasticSearch Cluster
여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합 (위키백과)
엘라스틱서치도 마찬가지로 여러 대의 노드들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하게 되어 있다.
이러한 특성에 의해 어떠한 노드에 어떤 요청을 해도 동일한 응답을 준다.
ElasticSearch Node
엘라스틱 클라스터는 여러 개의 노드가 존재하며 각각의 노드마다 역할이 있다.
- 마스터 노드
클러스터 상태 관리 및 메타데이터를 관리하는 노드이다. 마스터 노드와 마스터 후보 노드로 이루어져 있으며, 마스터 노드가 다운되면 마스터 후보 노드중 하나가 새로운 마스터 노드가 된다. - 데이터 노드
문서 색인 및 검색 요청 처리를 하는 노드 - 코디네이팅 노드
검색 요청 처리 역할을 하는 노드 - 인제스트 노드
색인되는 문서의 데이터 전처리 역할을 하는 노드로 어떤 문서가 ES에 색인이 되기 전 수정하는 역할을 한다.
Ex) 어떤 문서를 엘라스틱서치에 색인하기 전에 특정 필드의 특정 값들을 수정한 후에 색인
ElasticSearch Cluster 동작 구조

위와 같이 마스터 노드 3개, 데이터 노드 3개, 코디네이팅 노드 1개 총 7개의 노드가 있다. (마스터 노드는 하나 나머진 마스터 후보 노드)
# CASE 1
유저가 GET /book/_doc/1 이란 REST API로 마스터 노드 #0에게 요청을 보내는 상황을 예로 들어보자
이 때 문서를 가지고 있는건 데이터 노드이지만, 엘라스틱서치는 클러스터이기 때문에 어느 노드에 요청을 해도 무방하다.
마스터 노드가 GET 요청을 받으면 요청에 대한 문서가 위치한 데이터 노드로 요청을 전달하게 된다.
데이터 노드는 요청 받은 문서를 마스터 노드에게 전달하고 유저는 마스터 노드로부터 요청한 문서에 대해 응답을 받게 된다.
당연히 엘라스틱서치는 클러스터 구조이기에 마스터 노드가 아닌 데이터 노드에 같은 동일한 요청을 해도 동일한 응답을 받을 수 있다.
위처럼 마스터 노드에 요청을 해도 응답을 받을 수 있지만 마스터와 데이터 노드간 불필요한 트래픽이 발생하게 된다.
즉, 검색 요청을 처리하는 역할을 가진 데이터 노드나 코디네이팅 노드에 요청을 하는게 바람직 하듯이 각자 역할에 맞는 노드에 요청을 하는 것도 굉장히 중요하다.
# CASE 2
이번엔 코디네이팅 노드에 색인 요청을 하는 상황을 예로 살펴보자 (코디네이팅 노드 = 검색 요청 처리 역할을 하는 노드)
유저가 코디네이팅 노드에 PUT /books/_doc/2 요청을 하면 코디네이팅 노드는 해당 문서를 데이터 노드 전달하여 색인이 이루어진다.
결과적으로 엘라스틱서치는 클러스터 환경이기 때문에 어떤 노드에 어떠한 요청(색인, 검색 등)을 해도 무방하지만, 불필요한 트래픽을 줄이는 등의 이유로 각각의 노드가 본연의 역할에 충실할 수 있도록 구성하는 것이 중요하다.
위에 상황들을 모두 고려하여 엘라스틱서치 클러스터를 구축한다면 아래와 같은 환경으로 구축하는게 이상적일 것이다.
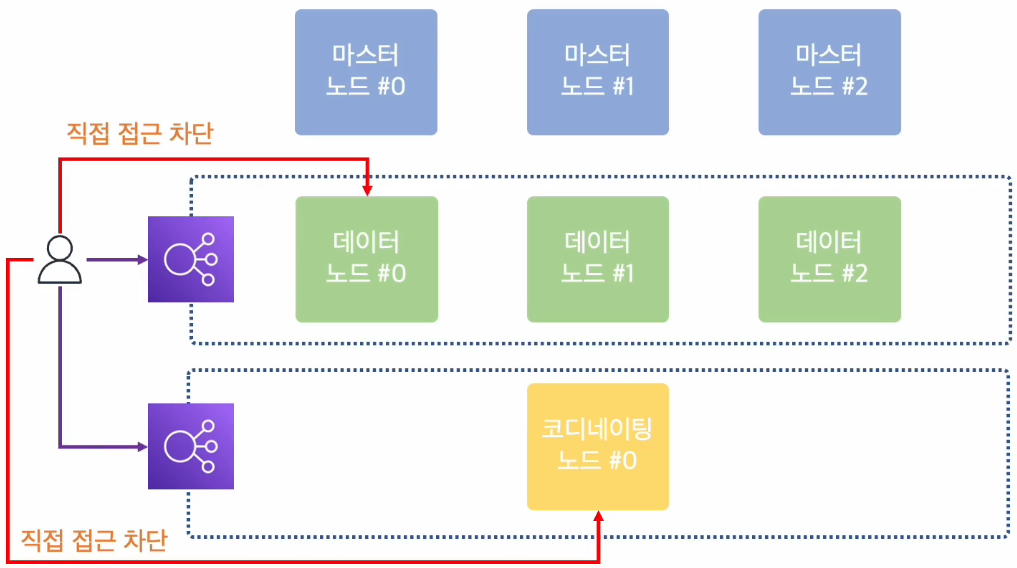
데이터 노드에 대한 직접적인 접근은 차단하고 앞단에 있는 LB를 생성하여 데이터 노드와 통신이 이루어지게 하고, LB의 엔드포인트 주소로 만 검색과 색인이 가능하도록 구성하는게 좋다.
코디네이팅 노드도 마찬가지로 노드 앞단에 LB를 생성하여 생성된 LB의 엔드포인트 주소를 통해서만 검색이 가능하게 구성하는게 좋다.
'DevOps > ElasticSearch' 카테고리의 다른 글
| [ElasticSearch] ElasticSearch 개념 (0) | 2024.05.13 |
|---|
